
V odborné diskusi o ochraně osobních údajů při využívání generativní AI se stále častěji objevuje tvrzení, že pro zajištění souladu s právními předpisy je „nutné upravit architekturu AI“. Tento argument zní přesvědčivě – evokuje představu, že samotný model nebo jeho technická podstata představují primární problém, který je třeba technicky přebudovat. Realita je však podstatně složitější.
Kde se v AI ve skutečnosti odehrává zpracování údajů
Většina organizací dnes neprovozuje vlastní velké jazykové modely (LLM). Organizace využívají generativní AI globálních poskytovatelů ve třech základních režimech: ve veřejném (public) režimu, v hybridním modelu nasazení (deployment) a v enterprise (self-hosted) režimu založeném na zvláštním licenčním a smluvním nastavení. V současnosti organizace převážně využívají veřejný (public) režim, v němž je model i jeho výpočetní infrastruktura plně pod kontrolou a v provozu poskytovatele služby.
Architektura samotného LLM je v takových případech mimo technický dosah zákazníka. To však neznamená, že je mimo jeho odpovědnost jako správce. Organizace nese odpovědnost za výběr poskytovatele, za smluvní rámec zpracování osobních údajů a za určení rozsahu údajů vstupujících do systému, bez ohledu na to, zda má možnost zasahovat do vnitřní struktury modelu.
Dodržování zásad zpracování osobních údajů a výkon práv subjektů údajů podle GDPR se nezajišťují „uvnitř modelu“, ale řízením datových toků, integračních vrstev a provozních nastavení na periferiích systému, v němž je model používán.
Následující blokový diagram znázorňuje základní logickou architekturu generativní AI se zaměřením na vztahy mezi komponentami a zejména na místa vzniku a ukládání dat.
Uvedené schéma je záměrně zjednodušené pro potřeby tohoto výkladu. V reálném provozu je aplikační architektura generativní AI podstatně komplexnější a zahrnuje množství dalších komponent a procesů včetně odvozených reprezentací vstupů uživatele (např. promptových struktur, vektorových reprezentací – embeddingů, provozních logů či mechanismů zpětné vazby využívaných při dolaďování modelů), stejně jako orchestraci požadavků, paměťové a kontextové vrstvy, vyhledávací mechanismy (např. RAG), vektorové databáze, bezpečnostní a validační filtry, autentizační a autorizační mechanismy, monitoring, auditní záznamy a integrační API rozhraní.
Generativní AI v praxi nepředstavuje jen jednoduché schéma „model + vstup + výstup“, ale vícevrstvý systém se samostatnými bezpečnostními, datovými a řídicími komponentami, které společně určují způsob zpracování údajů.
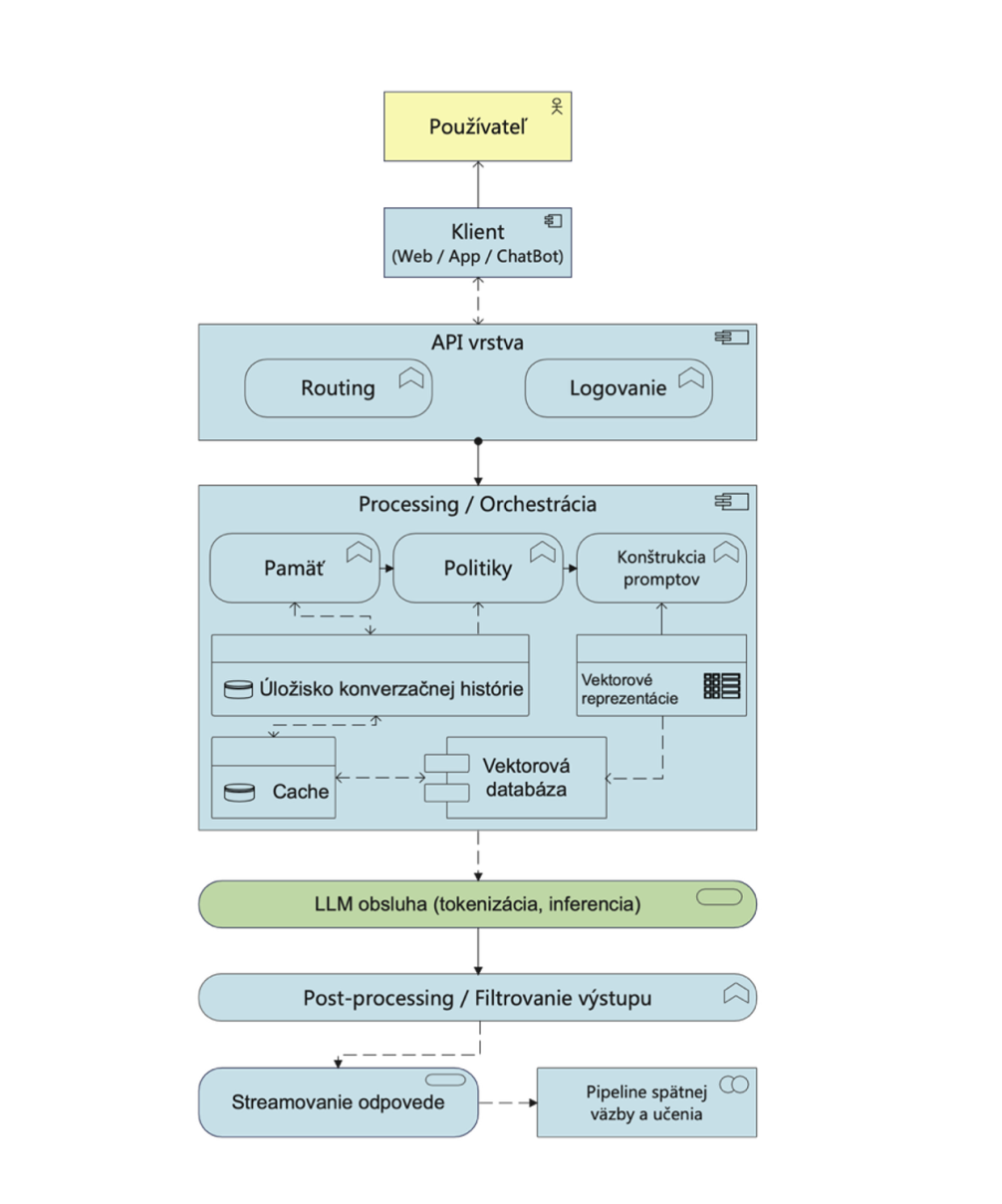
Z uvedeného zjednodušeného architektonického schématu lze vyvodit několik podstatných závěrů:
-
Vstup uživatele je zpracován aplikační vrstvou a odeslán modelu k inferenci (tj. k provedení modelu a generování výstupu na základě vstupu); pokud to konkrétní režim služby umožňuje, mohou být vstupní údaje nebo celá interakce uchovávány a následně použity jako součást dat využívaných k dolaďování nebo dalšímu tréninku modelu.
-
Systém v rámci zpracování generuje odvozené vektorové reprezentace vstupů (embeddingy) a další interní datové struktury včetně provozních metadat, jako jsou časové údaje, identifikátor požadavku, objem zpracovaných tokenů nebo stav zpracování.
-
Pokud je v daném režimu služby umožněn sběr interakcí, mohou být tyto údaje uchovávány a následně zařazeny do mechanismů zpětné vazby včetně datasetů využívaných ke zlepšování kvality modelu nebo jeho dalšímu dolaďování.
-
Tréninkové datové soubory jsou zpravidla uchovávány a zpracovávány v oddělených prostředích mimo produkční provoz; jejich využití vede k aktualizaci modelových parametrů jako celku, nikoli k úpravě jednotlivých záznamů.
Z hlediska ochrany osobních údajů je rozhodující právě poslední bod. Pokud se vstupní údaje stanou součástí tréninkových datasetů a následně se promítnou do modelových parametrů, přestávají být pod přímou kontrolou uživatele. Jejich individuální odstranění už nelze redukovat na jednoduchý úkon výmazu konkrétního záznamu, protože údaje se v rámci tréninkového procesu transformují do vektorových a následně parametrických reprezentací modelu. Nejde už o identifikovatelný záznam obsahující potenciálně osobní údaje. Ze záznamu se stává matematická reprezentace rozptýlená v modelových parametrech prostřednictvím aktualizace vah neuronové sítě, kterou nelze izolovat bez zásahu do modelu jako celku.
Technická realizace „zapomenutí“ konkrétních informací týkajících se identifikované nebo identifikovatelné fyzické osoby je po jejich zapracování do tréninku neuskutečnitelná. Jelikož tyto informace už neexistují jako samostatné údaje, ale jako součást matematické struktury modelu, jejich „zapomenutí“ by nebylo možné bez zásadního zásahu do modelu nebo jeho přetrénování. Experimentální metody machine unlearning zatím existují pouze teoreticky.
Je však třeba dodat, že v moderních enterprise režimech provozování AI k takovému využívání zákaznických vstupů pro trénink základních modelů nedochází, případně je možné je konfiguračně vyloučit. Riziko se pak v enterprise režimu váže zejména na případy, kdy je trénink nebo dolaďování ze vstupních dat výslovně povoleno.
Z technického hlediska platí jednoduché pravidlo: údaje, které uživatel do systému vloží, podléhají zpracování v rámci architektury systému navržené poskytovatelem. Uživatel přitom nemá možnost zasahovat do vnitřní struktury modelu ani do jeho tréninkových mechanismů.
Jak v praxi chránit osobní údaje v AI
Pokud akceptujeme, že architektura samotného LLM je mimo dosah uživatele, pak se těžiště ochrany osobních údajů přesouvá jinam. Praktická otázka proto nezní, jak změnit model, ale jak identifikovat a řídit konkrétní zpracovatelské operace v rámci jeho používání.
Jde zejména o:
-
vstupy uživatelů,
-
logování a monitoring,
-
paměťové mechanismy a konverzační úložiště,
-
retenční politiky,
-
smluvní nastavení rolí,
-
případné sekundární využití dat pro trénink nebo zlepšování služby.
Jinými slovy: rozhodující je způsob integrace modelu do podnikové architektury a způsob práce s daty. Bez ohledu na to, v jakém režimu je generativní AI implementována (public, hybridní nebo enterprise).
Základní princip: „nekrmit AI“
Z technického pohledu je nejspolehlivějším preventivním opatřením, jak zabránit neoprávněnému zpracování osobních údajů, to nejjednodušší – neposkytovat systému údaje, které tam nemají být.
Pokud osobní údaj nevstoupí do systému, nebude:
-
zaznamenán v logách,
-
zahrnut do odvozených vektorových reprezentací v LLM,
-
uložen v paměti ani v úložišti konverzační historie.
V takovém případě se nemůže stát předmětem budoucího neoprávněného zpracování.
Je však třeba rozlišovat mezi údaji, které do systému vědomě vkládá uživatel, a údaji, které může model generovat na základě svého předtrénovaného korpusu nebo odvodit inferencí.
Stejně tak v architekturách typu RAG (Retrieval-Augmented Generation) může docházet ke zpracování údajů z interních úložišť, i když nejsou přímo součástí promptu. V takovém modelu systém před generováním odpovědi vyhledává relevantní informace v externích nebo interních datových zdrojích (např. dokumentových úložištích či databázích) a tyto údaje následně vkládá do kontextu modelu jako součást vstupu. Model tak může zpracovávat i osobní údaje obsažené v interních systémech organizace, přestože je uživatel výslovně nezadal.
Prevence vstupu dat je účinnější než následné pokusy o jejich kontrolu nebo mazání. Jde o princip minimalizace, nikoli o absolutní vyloučení rizika.
V kontextu velkých modelů se výkon práva na výmaz může stát technicky extrémně komplikovaným, zejména pokud byly údaje použity při tréninku. V době AI se musíme definitivně přestat spoléhat na právo na zapomnění.
A) Konfigurační a smluvní opatření
Při využívání veřejných nebo enterprise SaaS řešení je třeba využít všechny dostupné konfigurační možnosti a smluvní nástroje, zejména:
-
vypnutí režimu „model improvement“,
-
deaktivaci nastavení „data sharing“,
-
vypnutí ukládání historie konverzací,
-
omezení retenční doby,
-
výslovné smluvní vyloučení použití zákaznických dat pro trénink nebo zlepšování modelu.
Všechna předchozí opatření závisejí na licenční politice poskytovatele modelu. Tato opatření nemění architekturu modelu, pouze omezují rozsah zpracování, které poskytovatel provádí.
B) Architektonické změny na straně zákazníka
Veřejný SaaS model typicky nemění architekturu pro konkrétního zákazníka. Změna se realizuje na straně uživatele, zejména:
-
vložením lokální kontrolní vrstvy před API (např. DLP filter, validační pravidla),
-
oddělením dokumentových úložišť a vyhledávacích mechanismů od samotného modelu,
-
centralizovaným řízením přístupů a evidencí používání,
-
omezením přímých přístupů uživatelů k veřejnému rozhraní služby.
V případě veřejných nebo enterprise SaaS řešení tedy nejde o úpravu architektury samotného modelu, ale o úpravu architektury podnikového informačního systému tak, aby se minimalizovaly rizikové vstupy a nekontrolované datové toky.
C) Specifika architektury RAG
Zvláštní pozornost si vyžadují architektury typu RAG (Retrieval-Augmented Generation), u nichž model před generováním odpovědi vyhledává relevantní informace v externích nebo interních datových zdrojích a tyto údaje následně vkládá do kontextu jako součást vstupu. RAG není jen funkční rozšíření modelu, ale rozšíření architektury zpracování údajů.
V takovém případě vzniká nový datový tok mezi interními úložišti organizace a modelem, který představuje samostatnou zpracovatelskou operaci.
Implementace RAG proto vyžaduje zvláštní technická a organizační opatření, zejména:
-
selekci a omezení dokumentů určených k indexaci,
-
sladění digitálních identit vyhledávacích mechanismů se stávajícími přístupovými právy uživatelů,
-
segmentaci a retenční pravidla datových zdrojů,
-
auditovatelnost retrieval operací,
-
kontrolní mechanismy bránící generování nadměrných nebo neoprávněných osobních údajů.
Co na to regulace?
Právo vždy bylo a bude do určité míry „druhé v pořadí“ vůči společenským potřebám a realitě. Ne proto, že by bylo méně důležité, ale proto, že přirozeně reaguje ex post – na své materiální prameny, na to, co už v praxi vzniklo a co společnost potřebuje upravit.
Právě proto nemůže být nikdy zcela všeobsahující ani detailně vysvětlující všechny technické nuance. A v oblastech, které se vyvíjejí exponenciálně – jako IT, kybernetická bezpečnost či AI – to ani nikdy nebude možné.
Právo pouze reaguje – popisuje a kodifikuje to, co už ve společnosti vzniklo. Netvoří společenskou realitu, ale reflektuje ji.
Regulační rámec Evropské unie tedy tuto otázku neřeší do detailu. Podle materiálu Orientations for ensuring data protection compliance when using Generative AI systems, od EDPS se názor právníků (v tomto případě) od mého až tak výrazně neliší.
Výkon práv subjektů údajů – včetně práva na výmaz nebo opravu – je zabezpečitelný. Tento předpoklad je normativní. Vyjadřuje stav, jehož má být dosaženo. Moje tvrzení nezpochybňují existenci ani platnost tohoto práva. Poukazují však na rozdíl mezi formální vykonatelností práva a jeho technickou realizovatelností v architektuře velkých generativních modelů.
Právo na výmaz vznikalo v prostředí klasických informačních systémů, kde osobní údaje existují jako identifikovatelné záznamy v databázích. V takovém prostředí je možné konkrétní údaj lokalizovat, odstranit a následně prokázat, že zásah byl proveden. Generativní model však funguje odlišně. Neuchovává údaje jako samostatné záznamy, neobsahuje „řádky“ ani „dokumenty“ a nepracuje se strukturovanými entitami. Informace jsou absorbovány do distribuce vah a pravděpodobností v parametrickém prostoru.
Po tréninku už neexistuje přímý mapovatelný vztah mezi konkrétním datovým bodem a konkrétní částí modelu. Údaj se nestává lokalizovatelným objektem, ale součástí matematické reprezentace. Technická otázka proto nezní, zda je výmaz právně požadován, ale zda je determinovatelné, co přesně má být z modelu odstraněno.
Regulační diskurz zároveň předpokládá existenci postupů pro výkon práv. V technologické realitě však neexistuje standardizovaný a obecně použitelný mechanismus selektivního odstranění konkrétního tréninkového údaje z foundation modelu s miliardami parametrů. Koncept tzv. “machine unlearning” je předmětem výzkumu, ale není operačním standardem komerčních LLM pipeline, není prokazatelně škálovatelný a neexistuje univerzální metodika, která by umožnila ověřit, že model daný údaj skutečně „zapomněl“.
Pokud je jediným spolehlivým řešením re-trénink modelu bez sporných dat, jde o zásah, který je extrémně nákladný, časově náročný a mimo kontrolu běžného uživatele SaaS služby. Tento stav není otázkou regulační ochoty, ale architekturního limitu současných modelů.
Regulační texty pracují i s hypotézou, že model nemusí být změněn, pokud „neobsahuje“ konkrétní údaj nebo z něj nelze údaje inferovat. Problém je, že inferenční schopnost modelu je probabilistická. Není binární. Model může určitou informaci reprodukovat ve specifickém kontextu, při určitém typu promptu nebo kombinaci vstupů. Negativní stav – tedy že model už konkrétní informaci nedokáže reprodukovat – není objektivně prokazatelný bez rozsáhlého a prakticky neomezeného testování.
Stejně tak je nutné rozlišovat mezi úrovní datasetu a úrovní modelu. Tréninkový dataset lze upravit, konkrétní záznam z něj odstranit a budoucí trénink může proběhnout bez daného údaje. To však neznamená, že již existující model byl efektivně „vyčištěn“. Výmaz na úrovni datasetu není automaticky výmazem na úrovni modelu.
Z provozního hlediska je situace ještě problematičtější. Běžná organizace, která využívá GenAI jako službu, nekontroluje trénink základního modelu, nemá nástroje k parametrickému zásahu a nedokáže nezávisle ověřit, že k selektivnímu „zapomenutí“ skutečně došlo. Pokud je výkon práva závislý na zásahu, který je mimo její kontrolu, ekonomicky nepřiměřený a technicky nejistý, pak je jeho praktická realizace v běžném SaaS prostředí výrazně omezená.
Regulace EU definuje cíl – zajistit výkon práv. Architektura foundation modelů však může vytvářet hranici, která tento cíl činí dosažitelným pouze částečně. Mé použití silné formulace o „neuskutečnitelnosti“ není odmítnutím právního rámce. Je poukázáním na fakt, že po zapracování údajů do váhového prostoru modelu neexistuje jednoznačný, deterministický a ověřitelný mechanismus jejich selektivního odstranění.
V této realitě se jako nejspolehlivější nástroj ochrany práv jeví nikoli ex post zásah, ale ex ante minimalizace vstupu osobních údajů. Nejde o popření práva na výmaz. Jde o konstatování, že v architektuře generativních modelů je prevence systematicky účinnější než dodatečný zásah do již natrénovaného systému.
Závěr
Chceme-li vést odbornou a odpovědnou diskusi, je třeba oddělit mýty od technické reality. Především je nutné si uvědomit, že ochrana osobních údajů v kontextu GenAI se neodehrává „uvnitř modelu“, ale v jeho integračním, datovém a provozním okolí. Klíčovou otázkou proto není, zda je třeba měnit architekturu umělé inteligence jako takové, ale kde přesně v reálném technickém a organizačním kontextu dochází ke zpracování osobních údajů.
Při využívání standardních SaaS řešení globálních poskytovatelů generativní AI zákazník architekturu základního modelu měnit nemůže. Diskuse o „nutné změně architektury AI“ je v těchto případech bezpředmětná. Organizace však může – a musí – upravit vlastní procesy, integrační vrstvy, konfigurační nastavení a pravidla práce s daty. Ochrana osobních údajů zde nezačíná rekonstrukcí modelu, ale rozhodnutím, jaké údaje do systému vstoupí a jakým způsobem budou dále zpracovávány.
Odlišná situace nastává u self-hosted modelů, vlastního fine-tuningu, budování embedding pipeline nebo implementace RAG architektur. V takových scénářích organizace zasahuje do architektury AI systému jako celku a odpovídá nejen za integrační vrstvy, ale i za samotné modelové a datové komponenty. Diskuse o úpravě architektury AI je proto relevantní právě tam, kde organizace architekturu reálně navrhuje, konfiguruje nebo modifikuje.
Právo na výmaz v kontextu generativní AI zůstává normativně platné. Otázkou však je jeho technická vykonatelnost v parametrických modelech velkého rozsahu – a právě na tento rozdíl má tvrzení upozorňují.
Pragmatický závěr je zřejmý: ochrana osobních údajů při používání generativní AI nezačíná rekonstrukcí modelu, ale rozhodnutím, jaké údaje do systému vstoupí. V konečném důsledku jde o datovou disciplínu, nikoli o změnu architektury LLM.